
Hadoop学习与部署
Hadoop介绍
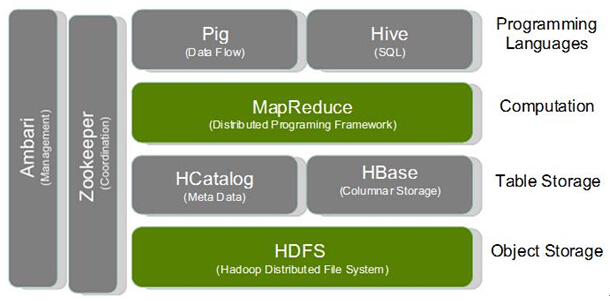
- Hadoop作为一个分布式的存储,计算平台,从底层到上层提供了丰富的开源项目,用户可以灵活选择组合搭配。HDFS是一个分布式的文件系统,MapReduce是一个分布式的程序框架。HDFS和MapReduce是本文档的研究对象,先从底层的HDFS,然后是上层的MapReduce。
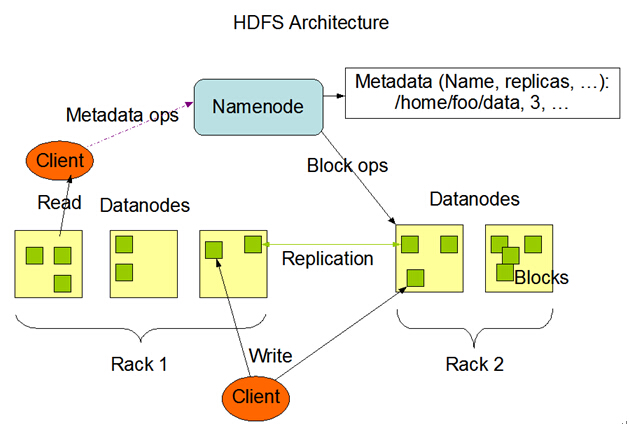
- HDFS介绍
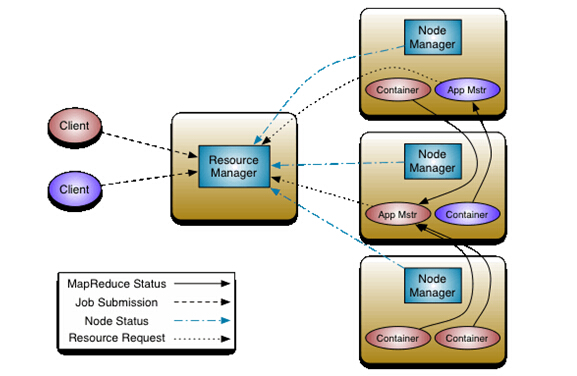
- MapReduce介绍 新版的hadoop里面,MapReduce的代号是yarn
- 主要单元介绍
单元 描述 NameNode 可以看成是HDFS的主机,保存了分布式文档的元数据,记录了文档分布在那些数据节点DataNode ResourceManager MapReduce的主机,负责分配任务调度 DataNode 数据节点,负责保存分布式的文档内容 NodeManager MapReduce资源节点,负责运行MapReduce任务 JournalNode 用于在节点之间共享数据,用于HA
测试环境
| 软件 | 版本 |
| Hadoop2.6 | 2.6 |
| OS | CentOS 6.4 |
| Java | java-1.6.0-openjdk |
测试架构图
 test
test
设备列表
| 功能单元 | IP | 描述 |
| Namenode(active) | 192.168.85.168 | 主机名 hadoop.namenode.1 |
| Namenode(standby) | 192.168.85.54 | 主机名 hadoop.namenode.2 |
| Datanode1 | 192.168.85.167 | 主机名 hadoop.datanode.1 |
| Datanode2 | 192.168.85.42 | 主机名 hadoop.datanode.2 |
| Datanode3 | 192.168.85.40 | 主机名 hadoop.datanode.3 |
基础配置
| 配置 | 命令 |
| 同步服务器时间 | yum install -y ntpdate ntpdate ntp.ubuntu.com |
| 禁止ssh反向解析 | vim /etc/ssh/sshd_config #增加 UseDNS no #reload配置文件 /etc/init.d/sshd reload |
| 修改主机名 | #修改上面设备列表各个功能单元服务器的主机名
vim /etc/sysconfig/network
#修改HOSTNAME字段为对应主机名#使主机名修改生效
hostname -v 主机名
sysctl kernel.hostname
修改主机名后,当前回话并没有改变,重新登录后回话会生效 |
| 配置hosts | vim /etc/hosts #增加各个服务器的主机名与ip关系 192.168.85.168 hadoop.namenode.1 192.168.85.54 hadoop.namenode.2 192.168.85.167 hadoop.datanode.1 192.168.85.42 hadoop.datanode.2 192.168.85.40 hadoop.datanode.3 |
| 安装jdk | #这里我们使用open jdk 1.6 yum install -y java-1.6.0-openjdk-devel |
| ssh免密码 | yum install -y openssh-clients
#在各个机器执行下面命令,一直回车到底 ssh-keygen -t rsa #进度.ssh目录 cd ~/.ssh/ cat id_rsa.pub >> authorized_keys #把其他机器的id_rsa.pub内容增加到自己的authorized_keys文件里面,然后验证服务器之间ssh是否免密码 |
| 端口互联 | #在iptable里面增加服务器之间能互联端口 -A INPUT -s 192.168.85.0/24 -j ACCEPT |
配置安装hadoop
- 下载hadoop #以下命令在namenode.1主机执行 cd /opt wget http://mirror.tcpdiag.net/apache/hadoop/common/stable/hadoop-2.6.0.tar.gz tar zxf hadoop-2.6.0.tar.gz
- 下载hbase #以下命令在namenode.1主机执行 cd /opt wget http://apache.mirrors.pair.com/hbase/stable/hbase-1.0.0-bin.tar.gz tar zxf hbase-1.0.0-bin.tar
- 设置环境变量 #以下命令在所有机器上执行 vim /etc/profile #增加以下内容到底部 export JAVA_HOME=/usr/lib/jvm/java export HADOOP_HOME=/opt/hadoop-2.6.0 export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar export HBASE_HOME=/opt/hbase-1.0.0 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar: export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin#是配置环境变量生效 source /etc/profile
- 设置hadoop-env.sh配置文件 #以下命令在namenode.1主机执行 cd /opt/hadoop-2.6.0/etc/hadoop # hadoop-env.sh #增加 export JAVA_HOME=/usr/lib/jvm/java
- 设置yarn-env.sh配置文件 #以下命令在namenode.1主机执行 cd /opt/hadoop-2.6.0/etc/hadoop # yarn-env.sh #增加 export JAVA_HOME=/usr/lib/jvm/java
- 设置core-site.xml配置文件
#以下命令在namenode.1主机执行
cd /opt/hadoop-2.6.0/etc/hadoop
vim core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> <description>hadoop临时数据目录</description> </property>
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop-test</value> <description>hadoop DFS名称</description> </property>
<property> <name>io.file.buffer.size</name> <value>4096</value> </property> </configuration>
- 设置hdfs-site.xml配置文件
#以下命令在namenode.1主机执行
cd /opt/hadoop-2.6.0/etc/hadoop
vim hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-test</value> <description>集群名称这里我们统一用hadoop-test,跟DFS一样</description> </property>
<property> <name>dfs.ha.namenodes.hadoop-test</name> <value>namenode1,namenode2</value> <description>集群包含的namenode id,这里我们只有两个namenode1 namenode2</description> </property>
<!--下面是分别配置namenode1 namenode2--> <property> <name>dfs.namenode.rpc-address.hadoop-test.namenode1</name> <value>HadoopNameNode1:9000</value> </property>
<property> <name>dfs.namenode.rpc-address.hadoop-test.namenode2</name> <value>HadoopNameNode2:9000</value> </property>
<property> <name>dfs.namenode.http-address.hadoop-test.namenode1</name> <value>HadoopNameNode1:50070</value> </property>
<property> <name>dfs.namenode.http-address.hadoop-test.namenode2</name> <value>HadoopNameNode2:50070</value> </property>
<!--这个是配置shared edits,每台机器都有Journal--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://HadoopNameNode1:8485;HadoopNameNode2:8485;HadoopDataNode1:8485;HadoopDataNode2:8485;HadoopDataNode3/hadoop-test</value> </property>
<!--这里我们没有用zookeeper,所以就配置为false--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>false</value> </property>
<!--journal数据目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/hadoop/dfs/journal</value> </property>
<!--checkpoint时间间隔,这里为了观察设置成60秒,真正使用配置成更长的时间--> <property> <name>dfs.namenode.checkpoint.period</name> <value>60</value> </property>
<property> <name>dfs.namenode.checkpoint.check.period</name> <value>60</value> </property>
<!--checkpoint保留edits文件数量多少,默认是100w个,这个太多了,这里我们配置100个方便观察--> <property> <name>dfs.namenode.num.extra.edits.retained</name> <value>100</value> </property>
<!--datanode的数据目录--> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/hadoop/dfs/data</value> </property>
<!--namenode的数据目录--> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/hadoop/dfs/name</value> </property>
<property> <name>dfs.replication</name> <value>2</value> <description>数据冗余</description> </property>
<property> <name>dfs.webhdfs.enabled</name> <value>true</value> <description>是否开启web接口</description> </property> </configuration>
- 设置yarn-site.xml配置文件
#以下命令在namenode.1主机执行
cd /opt/hadoop-2.6.0/etc/hadoop
vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>HadoopNameNode1</value> <description>ResourceManager运行在namenode1上面</description> </property>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<property> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property>
<property> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property>
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property>
<property> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property>
<property> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> </configuration>
- 设置mapred-site.xml配置文件
#以下命令在namenode.1主机执行
cd /opt/hadoop-2.6.0/etc/hadoop
vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
<property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property>
<property> <name>mapreduce.jobtracker.http.address</name> <value>HadoopNameNode1:50030</value> </property>
<property> <name>mapreduce.jobhistory.address</name> <value>HadoopNameNode1:10020</value> </property>
<property> <name>mapreduce.jobhistory.webapp.address</name> <value>HadoopNameNode1:19888</value> </property>
<property> <name>mapred.job.tracker</name> <value>http://HadoopNameNode1:9001</value> </property> </configuration>
- 设置slaves配置文件 #以下命令在namenode.1主机执行 cd /opt/hadoop-2.6.0/etc/hadoop vim slavesHadoopDataNode1 HadoopDataNode2 HadoopDataNode3
- 部署其它节点 #在NameNode1节点运行以下命令,把hadoop复制到其它节点 scp -r /opt/hadoop-2.6.0 hadoop.namenode.2:/opt/ scp -r /opt/hadoop-2.6.0 hadoop.datanode.1:/opt/ scp -r /opt/hadoop-2.6.0 hadoop.datanode.2:/opt/ scp -r /opt/hadoop-2.6.0 hadoop.datanode.3:/opt/
- 初始化hadoop
注意:以下所有操作均为第一次初始化hadoop所执行,之后的运行/关闭hadoop集群请参考运行/关闭hadoop#在所有机器上开启JournalNode
#运行下面命令,然后jps查看是否启动JournalNode进程
hadoop-daemon.sh start journalnode
#在HadoopNameNode1执行 hdfs namenode -format hadoop-daemon.sh start namenode
#在HadoopNameNode2执行 hdfs namenode -bootstrapStandby hadoop-daemon.sh start namenode
#把HadoopNameNode1设置成active hdfs haadmin -transitionToActive namenode1
#开启DFS,在HadoopNameNode1执行 start-dfs.sh #开启MapReduce Yarn,在HadoopNameNode1执行 start-yarn.sh
日常运维hadoop
- 启动hadoop集群 #在namenode1机器执行 start-all.sh
- 关闭hadoop集群 #在namenode1机器执行 stop-all.sh
hadoop实用命令
- 查看指定NameNode当前状态 hdfs haadmin -transitionToActive NameServiceID #使用这个命令,可以查看指定NameNode是active还是standby
- 配置指定NameNode状态 #把指定NameNode设置成active hdfs haadmin -transitionToActive NameServiceID#把指定NameNode设置成standby hdfs haadmin – transitionToStandbyNameServiceID
- 运行HDFS命令 hadoop dfs -fs hdfs://HadoopNameNode1:9000 -ls /
灾备与运维
- Namenode备机 NameNode作为整个HDFS的核心部分,要备份name数据和journal数据,它们的目录是hdfs-site.xml配置文件里面dfs.journalnode.edits.dir和dfs.namenode.name.dir。目前对于journal内容我们使用的是QJM的方式,也可以使用NFS的方式把name和journal文件同步到一台NFS备份服务器(在配置dfs.journalnode.edits.dir和dfs.namenode.name.dir的时候,除了写一个本次磁盘以外,还加一个挂载了NFS映射的目录,这hadoop每次写数据的时候会写多一份到NFS,多个目录使用逗号隔开),万一数据丢失了,可以从NFS备份服务器把这两个目录的内容拷贝过来,重新搭建namenode,也可以使用rsync把active的namenode机器这两个文件夹内容做rsync定时同步到备机。
- NameNode进程异常
进程异常是指,运行NameNode的设备正常(能SSH上),但是NameNode进程已经不能正常服务或者已经退出了。如果有异常的是standby namenode,则运行
hadoop-daemon.sh start namenode
如果异常的是active namenode,则运行 hdfs haadmin -failover —forceactive 异常NameNodeServiceID 新active NameNodeServiceID
如果需要更换NameNode设备,则参考下面NameNode设备异常
- NameNode设备异常 以下内容描述如何根据NameNode备份数据,重新部署NameNode设备。 根据hdfs-site.xml配置文件里面dfs.journalnode.edits.dir和dfs.namenode.name.dir两个目录路径,在备机建立一样的目录路径,把备份的journal和name内容拷贝到对应目录,然后把hadoop整个目录都拷贝到备机一样的路径和配置(具体参考配置按照hadoop部分),然后再次运行start-all.sh即可

