
提高测试效率的shell命令
2020-04-17 17:29:07 72
背景
目前大部分的项目都是部署在Linux系统上,作为测试,掌握常用Linux命令是必须的技能。常用ls、cd、cat等等这些命令,这些命令是可以应付工作的大部分场景。但在测试工作中很多情况下我们需要同文本文件打交道,如分析/统计日志、自动化部署等等,今天给大家介绍几个很实用的高阶文本处理命令。
cut
此命令的主要作用是来选取一段内容中我们想要获取的,通常选择信息是针对与“行”来分析的,擅长处理“以一个字符间隔”的文本内容。
语法格式:
$ cut -c 字符区间
$ cut -d “分隔字符” -f fields
示例: 新建练习文件,内容如下
[root@localhost shellTest]# cat test.txt
01 nick 20
02 rose 25
03 jack 30
04 tom 27
1、显示每行第四个字符之后的内容
[root@localhost shellTest]# cut -c 4- test.txt
nick 20
rose 25
jack 30
tom 27
#说明:
# 4- 表示从第4个字符开始
# 4-10 表示从第4个字符到第10个字符
# -4 表示截取前4个字符
2、以“空白字符”作为分隔符,显示第二列内容:
[root@localhost shellTest]# cut -d " " -f 2 test.txt
nick
rose
jack
tom
sort
将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按照ASCII码值进行比较,最后将他们按升序输出。
语法格式:
$ sort [-nrtk] [file]
以那个区间来进行排序
示例: 还是依据上述的test.txt文件
1、以空白字符作为分隔符,将第二列内容进行升序排列
[root@localhost shellTest]# sort -t " " -k 2 test.txt
03 jack 30
01 nick 20
02 rose 25
04 tom 27
2、以空白字符作为分隔符,将第三列年龄字段进行降序序排列
[root@localhost shellTest]# sort -t " " -k 3 -nr test.txt
03 jack 30
04 tom 27
02 rose 25
01 nick 20
# 说明:
# 年龄字段是数字类型,所以需要加参数n
# 默认sort是升序排列,加参数r实现降序排列
uniq
过滤文件中重复部分,经常结合sort一起使用(重复数据相邻的)
语法格式:
$ uniq [-icu]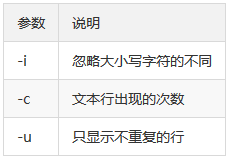
示例: 新建文本文件如下
[root@localhost shellTest]# cat test2.txt
01 nick 20
02 tom 25
03 jack 30
04 rose 25
03 jack 30
1、去除姓名重复的数据 结合sort排序和uniq去重(去重的前提是要重复的数据相邻)
[root@localhost shellTest]# sort test2.txt | uniq
01 nick 20
02 tom 25
03 jack 30
04 rose 25
2、统计每行出现的次数
[root@localhost shellTest]# sort test2.txt | uniq -c
1 01 nick 20
1 02 tom 25
2 03 jack 30
1 04 rose 25
wc
统计文件里面有多少行,多少单词,多少字符
语法格式:
$ wc [-lwm]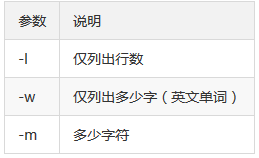
示例: 还是以test2.txt文件举例
1、统计文件中的行数
[root@localhost shellTest]# wc -l test2.txt
5 test2.txt
2、统计有多少个字符
[root@localhost shellTest]# wc -m test2.txt
55 test2.txt
睿江云官网链接:www.eflycloud.com

