字符处理工具之--awk命令初步使用
Awk简介:
Awk报告生成工具,它能够把文件读取到每一行的每一个字段进行格式化输出显示,以让报告生成更加直观。严格而言,它是一种完整的编程语言,绝大多数功能都是围绕文本格式化而展开。
它需要事先确定字段分隔符,才能分割字段。它可以自行指定分隔符,让每个字段进行处理,因此也称为格式化打印。
内部必须按条件完成字段获取,处理。因此内部支持使用变量,支持自定义函数,支持使用条件判断,循环和数组。
后期awk融入了许多新功能,称为new awk nawk。不过由于awk已经为众人所熟悉,许多操作系统中awk链接到了nawk。
而在Linux系统上,使用GNU awk,gawk。
语法:
Awk [options] ‘scripts’ FILE …awk [options] ‘/pattern/{action}’ FILE…
默认action是print,显示。比如print $1。
选项: -F:指定分隔符,自动将一行切割成n段,并且将每个字段使用变量表示,比如4段分别表示为$1,$2,$3,$4。如果引用整行,则使用$0
FS:输入分隔符,默认为空格。
模式: 地址定界模式:/pat1/,/pat2/… 范围匹配。在地址定界前加!,表示取反。
/pattern/:只能被模式匹配的行
Expression:表达式,如>,>=,<,<=,==,!=,~(模式匹配)
BEGIN:执行前的准备工作
END:执行后的收尾工作
Awk默认工作在遍历模式下,自身会循环文件的每一行。每次读一行切片进行处理。如果赋予定界机制,则仅处理符合定界的行而打破其遍历机制。
Awk变量: Awk内置变量之记录变量:
FS:field separator 读取文本时,所使用字段分隔符
RS:record separator 输入文本信息所使用的换行符
OFS:output field separator
ORS:output row separator
Awk内置变量之数据变量:
NR:The number of input record awk命令所处理的记录数。如果有多个文件,这个数目会把处理的多个文件中行统一计数
NF:Number of Field 当前记录的field个数
FNR:与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数。与NR不同,这是单独文件计数。
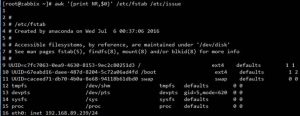
ARGV:数组,保存命令行本身这个字符串。如 awk ‘{print $0}’ a.txt b.txt这个命令中,ARGV[0]保存awk,ARGV[1]保存a.txt
在BEGIN模式下输出,而此变量输出结果为awk,空白。

0表示awk,1表示fstab,2表示issue

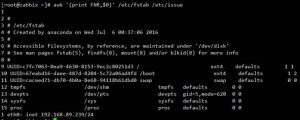
ARGC: awk命令的参数的个数
3表示三个参数:awk,/etc/passwd,/etc/group
FILENAME:awk命令所处理的文件的名称

ENVIRON:当前shell环境变量及其值的关联数组
如:
[root@zabbix ~]# awk 'BEGIN{print ENVIRON["PATH"]}'
/usr/lib64/qt-3.3/bin:/usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/workRec:/root/bin
Printf
Printf命令的使用格式:Printf format,item1,item2,…
要点:
其与print命令的最大不同是,printf需要指定format
Format用于指定后面的每个item的输出格式
Printf语句不会自动打印换行符:\n
Format格式的指示符都以%开头,后跟一个字符。如下:
%c:字符的ASCII码
%d,%i:十进制整数
%e,%E:科学计数法显示数值
%f浮点数:
%g,%G:以科学计数法的格式或浮点数的格式显示数值
%s:显示字符串
%u:无符号整数
%%:显示%自身
修饰符:
N:显示宽度
-:左对齐
+:显示数值符号
比如:
以数字形式显示,默认不换行
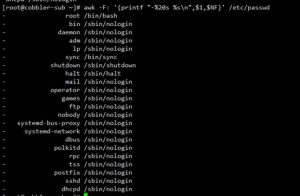
左对齐,并且之间空20个字符,以string形式输出: